Agent Skills 是一种将程序性知识标准化封装的方式。简而言之,它解决的不是“有没有工具”,而是“如何把工具用对、用好”。
1. 核心设计理念
Agent Skills 的核心价值在于沉淀“方法论”:
- 提供领域知识,指导智能体在具体场景下如何组合与调用工具。
- 约束执行路径,减少试错成本,提升任务完成的一致性。
- 让复杂流程可复用、可迭代,逐步形成稳定 SOP。
如果把工具能力比作“硬件接口”,那么 Skills 更像“操作说明书”与“最佳实践集合”,定义的是“该怎么做”。
2. 渐进式披露:破解上下文困境
Agent Skills 最核心的创新是渐进式披露(Progressive Disclosure):按需加载信息,避免一次性把大量内容塞进上下文窗口。
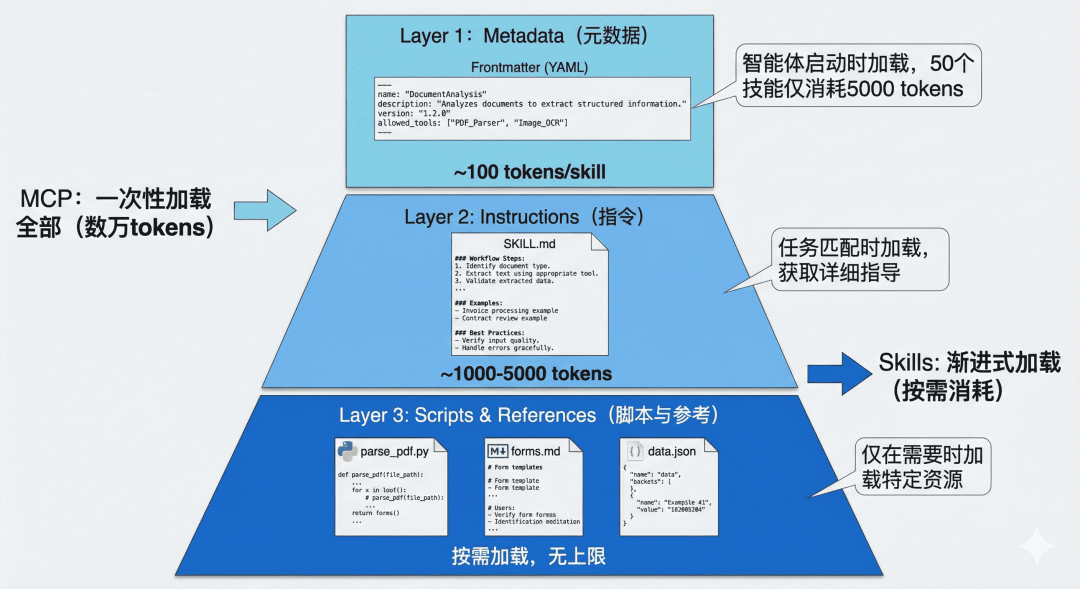
2.1 第一层:元数据(Metadata)
每个技能通常位于独立文件夹中,核心文件是 SKILL.md。该文件以 YAML Frontmatter 开头,定义技能基础信息。
智能体启动时,只读取所有技能的 Frontmatter 并注入系统提示词。根据实践经验:
- 单个技能元数据消耗约
100 tokens - 50 个技能约消耗
5,000 tokens
2.2 第二层:技能主体(Instructions)
当某个技能被判断为与当前任务高度相关时,智能体才会读取完整 SKILL.md,加载详细指令、注意事项和示例。
这部分 token 消耗通常与技能复杂度相关,常见范围为:
1,000到5,000 tokens
2.3 第三层:附加资源(Scripts & References)
复杂技能可在 SKILL.md 中引用脚本、配置和参考文档,仅在需要时加载。
示例目录结构:
|
|
典型调用方式:
- 需要解析 PDF 时,执行
parse_pdf.py - 遇到填表任务时,再加载
forms.md - 模板文件仅在输出特定格式文档时访问
3. 为什么这种设计有效
3.1 可扩展的知识容量
通过“脚本 + 外部文件”,技能可携带远超上下文窗口容量的知识。
例如,一个数据分析技能可以附带 1GB 数据文件和查询脚本,智能体通过执行脚本访问数据,而不是把整份数据集直接塞进上下文。
3.2 更强的确定性
将复杂计算、数据转换、格式解析交给代码执行,可以显著降低 LLM 在纯文本生成中的不确定性与幻觉风险。
4. 实际效果:从 16k 到 500 Token
社区实践显示,渐进式披露能显著降低初始上下文开销:
- 传统 MCP 方式:直接连接包含大量工具定义的 MCP 服务,初始化约
16,000 tokens - Skills 包装后:先用轻量 Skill 作为“网关”,仅通过 Frontmatter 描述能力,初始化约
500 tokens
当任务真正需要时,再按需加载详细指令与附加资源。这样既降低了初始成本,也让对话过程中的上下文管理更精准。
总结
Agent Skills 的关键意义在于:把“工具可用”升级为“能力可复用”。通过渐进式披露,系统可以在保持能力深度的同时,显著优化 token 成本与执行稳定性。